Webブラウザのブックマークレット機能でニュース記事のテキストを抽出してみる
岩手県立大学とか、岩手の人たち Advent Calendar 2022 23日目の記事です。今日はニュース記事をテキストとして抽出する話をしようと思います。
ニュース記事のブックマーク
ネット上で見かけて気になったり、後から参照しそうな記事をブックマークしておくことは良くあるかと思います。しかし、記事によっては掲載期間が過ぎると閲覧できなくなるものもあり、時間が経ってからブックマークを開くと「記事が見つかりません」という表示がされて残念な気持ちになることがあります。
その都度、Webページを保存したりテキストで手元にコピペしておけばよいのですが、数が多くなるとこれも面倒です…。Webスクレイピングでテキスト抽出、という方法もありますが、昨今のニュース記事のWebサイトはJavaScriptで表示制御されていることも多く、いつでも適用できる方法ではありません。
Webブラウザのブックマークレット機能
ところで、Webブラウザでは「ブックマークレット」という機能があり、ブックマークから小さなJavaScriptプログラムを動かすことが可能です。この機能の嬉しい(面白い?)点として、ブックマークレットを走らせると、ユーザが現在閲覧しているWebサイトでJavaScriptを動かせるというものがあります。これを応用して、ニュース記事のWebサイトから記事のテキストを抽出することもできそうです。
ブックマークレットの作り方
ブックマークレットの作り方は簡単で、ブックマーク作成時にURLの部分に javascript:<任意のJavaScript> を設定するだけです。エディタ等でスクリプトを作成しておいたコードをコピペするのがお手軽な作成方法です。

ニュース記事からテキストを抽出するブックマークレット用スクリプト
今回は例として、Yahoo! Japan ニュースからニュース記事をテキストで抽出するサンプルを作成してみます。
サンプルコードは以下になります。ポイントとしては、 window.location で現在閲覧しているURLを取得し、それが対象のURLかどうかを判定することで、関係のないWebページでこのスクリプトの処理が走ってしまうことを防止しています。それ以外は単にWebページ内のHTML構造を document.getElement*() 系の関数でアクセスし、タグ内のテキストを取得しているだけです。
/* Yahooニュース(https://news.yahoo.co.jp/)の記事をテキスト形式で取得するブックマークレットです */ javascript:(function() { /* 現在のWebページのURLを取得する */ let url = window.decodeURI(window.location.toString()); /* 現在のWebページがYahoo!ニュースの記事ページかどうか判定する */ if (url.match(/^https:\/\/news.yahoo.co.jp\/articles\//) != null) { /* Yahoo!ニュースの記事ページなら、記事の内容をHTMLタグから抜き出す * HTMLタグについているclass名を用いてタグを絞り込む */ let title = document.getElementsByClassName('sc-gpHHfC')[0].innerText; let date_time = document.getElementsByClassName('sc-kQsIoO')[0].innerText; let body = document.getElementsByClassName('sc-jtggT'); let chapter = document.getElementsByClassName('sc-gmeYpB'); /* 抜き出したニュース記事をテキスト形式に整形する */ let text = `${title}\n`; text += `${date_time}\n\n`; for (let i in body) { if (body[i].innerText == undefined) { continue; } if (i > 0 && i < chapter.length) { /* 記事の小見出しを含む場合は「■」で小見出し部分を強調する */ text += `■ ${chapter[i-1].innerText}\n${body[i].innerText}\n` } else { /* 記事本文のみの場合 */ text += `${body[i].innerText}\n\n` } } alert(text); } })()
実際にこのブックマークレットを動かしてみると、以下のようにニュース記事のテキストが抽出できます。このテキストをHTTP POSTで受け取って保存するようなWebAPIを作成しておくとさらに便利でしょう。 (ただし、あくまでも個人用途での利用のみに留めるのが良いかと思います)

まとめ
ブックマークレット機能を利用して、ニュース記事のテキストを抽出する例を紹介しました。Webページの情報を抽出するというケースにおいては、Webスクレイピングがお手軽ですが、JavaScriptで表示内容が制御されているような場合は、そのWebサイトのみで動作する形のブックマークレットを作成し、JavaScriptでHTML構造にアクセスするのが手段としては適切ということもあったりします。
Webコミックが更新されたかどうかを自動的にチェックしてみる
岩手県立大学とか、岩手の人たち Advent Calendar 2022 16日目の記事です。今日はWebコミックの更新確認をお手軽に行う方法を紹介しようと思います。
15日目の記事ではWebコミックの更新日を確認する方法を紹介しましたが、Webサイトによっては、そもそも次回更新日が記載されていない場合もあります。今回は、(私は単行本で読んでいるのですが)「ワカコ酒(ゼノン編集部)」を例に更新確認を行う方法を紹介しようと思います。
Webページの構造を把握する
さっそくWebページの構造を把握してみます。コミックぜにょんのWebサイトを見ると、第1話と最新話へのリンクがあり、最新話のURLは都度変わるという構成になっています。
このような場合は、「変わらないもの」に着目することで欲しいデータを引っかけるためのキーワード代わりにできます。今回の例では、「第1話」のURLは変わらないでしょうから、このURLをキーワードにできそうです。
URLはHTMLの a タグに記載され、 <a href="<URL>">ワカコ酒</a> のような記述になるため、URLとタイトルでgrepすると最新話のURLが取得できます。
$ curl -s https://comic-zenon.com/series/zenyon | grep -A3 'https://comic-zenon.com/episode/10834108156688950516.*ワカコ酒' <h4 class="item-series-title"><a href="https://comic-zenon.com/episode/10834108156688950516">ワカコ酒</a></h4> <p class="item-series-author">新久千映</p> <div class="panel-tag zenyon"> <p>グルメ</p> <p>おひとり様</p> <p>TVドラマ化</p> </div> <div class="panel-button"> <a href="https://comic-zenon.com/episode/10834108156688950516">1話へ</a> <a href="https://comic-zenon.com/episode/316190247005800487">最新話へ</a> </div>
こんな感じですね。この処理を一日一回走らせる等しておき、取得・保存しておいたURLと比較することで、URLが異なっていたら最新話が更新された、と判断できます。
$ curl -s https://comic-zenon.com/series/zenyon \ | grep -A3 'https://comic-zenon.com/episode/10834108156688950516.*ワカコ酒' \ | tail -n1 \ | sed \ -e "s/\">最新話.*$//" \ -e "s/^.*http/http/" https://comic-zenon.com/episode/316190247005800487
まとめ
Webコミックの更新確認を行う方法の一つとして、最新話のURLを用いる方法を紹介しました。Webスクレイピングでデータ取得して以前のデータと比較するという、地味な方法ですが、チェックしたいWebコミックが多くなってくるとこのシンプルな実現方法の楽さが嬉しく思えてくるかと思います。
Webコミックの次回更新日をWebスクレイピングで取得してみる
岩手県立大学とか、岩手の人たち Advent Calendar 2022 15日目の記事です。今日はWebで公開されているマンガの次回更新日をWebスクレイピングで取得する話をしようと思います。
Webコミックの次回更新日
私が読んでいるWebコミックの一つに「邪神ちゃんドロップキック(COMICメテオ連載)」があります。Webでマンガが読めるのはありがたいのですが、次にマンガが更新される日付を見落としがちだったりします…。こまめにWebサイトを確認すれば良いのですが、確認しに行ってまだ更新されていないとちょっと残念な気持ちになるので、自動的に次回の更新日を把握しておきたいものです。Webサイト上には「次回は○月×日更新」といった記述があるため、この情報を取得できればよさそうです。
Webスクレイピングで次回更新日を取得してみる
さっそく「邪神ちゃんドロップキック」のWebサイトのHTML構造を見てみます。更新日の表示は「次回は○月×日更新!」という形式になっているので、単純に「次回は」というキーワードでgrepしてみます。前後のHTMLを見ると、 <div class="work_next_update_txt"> タグの一行下に次回更新日が記載されています。
$ curl -s https://comic-meteor.jp/jyashin/ | grep -B4 -A4 次回は <div class="work_next_update"> <!-- 最新の投稿を表示 --> <div class="work_next_update_txt"> 次回は12月28日更新! 単行本20巻&ムック好評発売中! クラウドファンディング大反響実施中! </div> <div class="work_next_update_txt"> </div> <!-- 投稿記事数の判定終了 --> <!--次回は4月更新予定! ☆TVアニメ化決定ですの!☆特集ページもチェック!☆最新情報は公式twitter(@jashincyan)にて。--> </div><!-- work_next_update end --> <script src="https://comic-meteor.jp/jyashin/wp-content/themes/comic-meteor-child/indexPage.js"></script> <div class="work_episode">
というワケで、以下のようにすると無事に次回更新日が取得できました。
$ curl -s https://comic-meteor.jp/jyashin/ \ | grep -A1 '^ <div class="work_next_update_txt">' \ | tail -n1 \ | sed \ -e "s/更新.*//" \ -e "s/^.*次回は//" 12月28日
まとめ
Webコミックの次回更新日を取得する方法を紹介しました。小技チックな手法ですが、HTMLの構造次第では今回の例のように、簡単な文字列置換のみで目的が達成できたりします。 (なので、簡単なシェルコマンドを覚えておくのは意外と有用だったりします)
点字翻訳アプリのサンプルを作ってみました
岩手県立大学とか、岩手の人たち Advent Calendar 2021 3日目の記事です。 今日はシニアプログラミングもくもく会でJavaScriptを使った簡単なアプリ作成を行った話をしようと思います。
シニアプログラミングもくもく会
シニアプログラミングもくもく会は、シニア(高齢者)の方のプログラミング学習を支援するコミュニティーで月イチの頻度でもくもく会が開催されています。もくもく会では、プログラミング言語に応じて複数の部屋(現在はZoomを使っており、ブレイクアウトルームに分かれてもくもく会する感じになっています)が用意されています。
シニアの方だけでなく、一般の方も参加可能であるため、私も少し前から参加させてもらっていて、Glideというノンプログラミングツールのもくもく部屋を開催していました。
ただ、参加者の方が作ってみたいアプリをヒアリングしてみると、Glideのユースケースにマッチするものとそうでないものがあり、まずはいくつかの小さなアプリを題材としたプログラミングが良いのではないかと思うようになってきました。 (個人的にはちょっとした面倒ごとを解消するようなアプリだとプログラミング学習のモチベーションが上がるような気がしています)
というワケで、前々回くらいからJavaScript部屋を開催させてもらっており、今回はそこで作成した簡単なアプリの紹介をしてみます。
点字翻訳アプリ
少し前の話ですが、日本盲導犬協会の方が以下のようなツイートをしていました。どうやら11月1日は日本点字制定記念日のようです。
📣11/1は「日本点字制定記念日」
— 日本盲導犬協会 (@JGDA_GuideDog) 2021年11月2日
皆さんがいつも使っているモノ、建物など身近なところにも実は点字があるんです。#日本盲導犬協会 の職員名刺にも点字を使っていますが、何が書いてあるでしょうか?
ぜひ一覧表を使って読んでみてください! pic.twitter.com/y8iDO18DNG
このツイートに点字の一覧表が添付されており、「これを使用すれば点字を読み解けるのでは…!」と閃いたワケです。機能的にも比較的小さなプログラムで実現できそうであり、さっそくJavaScript部屋でのアプリの題材にしてみました。
アプリの構成
JavaScript自体はWebブラウザさえあれば試すことができますが、実際に作成したプログラムの共有はもう一工夫必要です。JavaScript部屋ではcodepen.ioでプログラムを共有することにしました。
今回作成した点字翻訳アプリは以下のURLで試すことができます。
See the Pen 点字翻訳アプリ by furandon_pig (@furandon_pig) on CodePen.
サンプルということもあり、ア~オまでの点字のみの翻訳となっていますが、基本的な機能は実装済みです。 点字の入力をどうするか、という点がネックでしたが、点字の入力欄に見立てた2列3行の入力欄をクリックすることで点字の凹凸(「‐」と「●」)がトグルするようなユーザインタフェースにしてみました。
点字が入力される度にデータとして持っている点字リストと比較し、一致する文字があればそれを表示する、という動作にしてみました。
HTMLとJavaScriptを合わせても60行ちょっとなので、だいぶコンパクトなプログラムになっています。 (あとは点字のデータを一通りそろえれば十分に実用的なアプリになります)
できるだけシンプルな構成にする
この点字翻訳アプリですが、 document.getElementById() によるDOM操作等、あえて古めかしい書き方をしている部分もあります。最新のJavaScriptの機能やフレームワークも良いのですが、プログラミンを学び始める際には逆に憶えることが増えてしまう場合もあります。
そのため、「こうすればこのような動作になる」という具体的な動作イメージを掴んでもらいやすくするため、ちょっと古めかしい書き方であってもアプリの振る舞いについて流れが追いやすいようなサンプルにしています。
まとめ
簡単ではありますが、シニアプログラミングもくもく会で作成した点字翻訳アプリとJavaScript部屋の紹介をしてみました。
codepen.ioは初めて使ってみたのですがなかなか便利です。特に小さなアプリの作成とプログラムの共有がJavaScript部屋でのユースケースにうまくマッチしています。 他にも小さなアプリの題材を見つけてプログラムのサンプルを増やして行きたいところです。
クマ研講演会~みんなの知らない野生動物の世界~(2019)に参加してきました
岩手大学 Advent Calendar 2021 2日目の記事です。今日は以前に岩手大学で開催された「クマ研講演会~みんなの知らない野生動物の世界~」という公開講座に参加した時の話をしようと思います。
クマ研講演会
少し前の2019年11月の話になりますが、岩手大学で「クマ研講演会~みんなの知らない野生動物の世界~」という公開講座が開催されました。面白そうな講演会であったため、ふらりと参加してみました。
クマ研講演会に向かう
クマ研講演会は2019年11月16日(土)の13:00開始であったため、まずはお昼ご飯をすませてから会場に向かうことにしました。 お昼は中津川の近くにある中河(なかがわ)に立ち寄ってみました。メニューはラーメンだけという昔ながらの硬派(?)なお店でです。 (残念ながら、当時の段階で店内での撮影はNGになっていました…)


あとはそこから会場の岩手大学まで散歩を兼ねて歩きます。運の良いことに中河から通りに出た道を道なりに歩いてゆくと岩手大学に辿り着けるようです。

岩手大学に着いた後は講演会の案内ポスターを頼りに会場に向かいます。


岩手の森のけもの達~その生息の実態は今~
公開講座の内容はいくつかあったのですが、今回のその中の「岩手の森のけもの達~その生息の実態は今~」の紹介をしようと思います。
岩手県に生息する野生動物(哺乳類)は45種類あり、以外(?)なことに一番多い種類はコウモリ目とのこと。 (てっきりクマかシカ類が多いのかなと思っていました…) そして参考までに、鹿児島県の場合は39種類とのこと。
| 野生動物 | 種類 | 備考 |
|---|---|---|
| モグラ・トガリネズミ目 | 7種 | |
| ウサギ目 | 1種 | |
| ネズミ目 | 8種 | |
| コウモリ目 | 17種 | 13種がレッドデータ種になっている |
| サル目 | 1種 | |
| 食肉目 | 8種 | |
| ウシ目 | 3種 |
また、市街地でよく見かけるのは「アブラコウモリ」という話でした。
コウモリの話
コウモリは大食漢?
コウモリ目が一番多いという点から、コウモリの習性について解説されていました。
コウモリは大食漢であるらしく、例えばユビナガコウモリが住処の洞窟からエサを採りに出かける前(出洞前)の体重は13gほどでありながら、帰って来た時(帰洞後)は16gになっていたり、ドーベンコウモリの例では7g~12gの変動幅で、最大8gのユスリカ捕食例もあるのだとか。この大食漢っぷりは、計算上だと体重45gのヤマコウモリが400匹分のタマバエ(20g)を捕食できることになり、ヤマコウモリが50匹いたら、一晩に20,000匹のタマバエを捕食できるという計算になります。
これはコウモリ目が昆虫類の大量発生抑制に多大な貢献を果たしているという話でもあり、健全な農林業への大きな役割を果たしているとも言えます。 日本では試算されていないとのことですが、アメリカの試算では農業被害軽減効果は最低でも年37億ドル(4000億円)にもなるとのこと。
コウモリの保全に関する課題
ところが、日本においてはコウモリの保全に関する課題は山積みとのことで、森林性コウモリの場合は繁殖・休息場所の減少が挙げられます。これについては、例えば乗鞍高原にバットハウスがあったりします。 また、トンネルの改修等で天井をツルツルにしてしまうとコウモリがつかまれなくなってしまうため、「コウモリピット」を設置して止まりやすいようにしたりしたり、メッシュタイプのコウモリピットを用意したりするとのこと。 そして、欧米はコウモリ保全の先進国とのことで、イギリスではコウモリが屋根裏に入りやすいように出入り可能な瓦が販売されているのだとか。
加えて、クリーンな発電方法として風力発電が挙げられますが、バードストライクと同じく、バットストライクも風力発電の進展と共にコウモリの保全に対して深刻な影響を与える可能性が考えられるというお話でした。 (全てにおいてベストな解決策というものは存在しないという話ですね…)
岩手県で近年問題になっている動物たち
ハクビシンの話
コウモリの話の次は、岩手県で近年問題になっている動物たちの解説が行われました。 ツキノワグマによる被害はニュースでも耳にするのですが、それ以外の動物による被害はあまりニュースにはなりませんね…。
まずはハクビシンの話がありました。どうやらハクビシンは甘いものが大好きで何でも食べ、しかも昆虫、ニワトリ、カエルなど何でも食べる悪食(?)とのこと。はては里芋の芋がらまで食べるらしく、食べ物の半分は人間由来のエサになっているとのこと。 さらに、人間由来の資材、廃屋などがハクビシンの格好のねぐらになっており、例えば古い神社のお社などがねぐらになっているというお話でした。
ツキノワグマの話
ツキノワグマの話もあり、今年(当時は2019年)も出没・駆除が頻発しているという話でした。 岩手県は広いというか、東西に大きな山脈が分かれており、同じ岩手県でも、北上高地と奥羽山地でツキノワグマに遺伝的な差があり、北上高知(北上山地)ではアルビノのクマの発見率が多いとのこと。 また、クマは蛇が嫌いらしく、どうやらこれは本能的な習性ではないかとの解説がなされていました。 ニュースを見ていると、頻度の差はあれ定期的にクマのニュースが出ているという印象はあり、特にブナが不作の時にはクマが多く出てくる気がしますが、実際のところ、東北でクマの駆除が多いのは夏(7~10月)であり、この季節はブナの実はなっていないため、別の要因ではないかとの話でした。 (講演者の方が「これは別の機会に…」と話されていたので、次回のクマ講演会が待たれるところです) そして、クマに縄張りはあるか?という話があり、クマの行動圏は重複しているため、一頭駆除しても代わりがたくさんいる、なので駆除したから即安心、という話でもないとのことでした。
昨今の農業就業者数の減少により、畑が廃棄されるケースが増えており、廃棄された畑はすぐ荒れてしまいバッファゾーン(※)ではなくなってしまうので、クマが通れるようになってしまう。 ※:農道等で道ができていると、クマは緑が無いところを警戒して道を横切って超えてこない、という話でした。
結局のところ、クマの駆除だけでは被害はなくすことはできず、森の整備、そしてクマを里に誘因する原因の除去など「総合的な施策」が欠かせないという話で解説が締めくくられていました。
まとめ
「クマ研講演会~みんなの知らない野生動物の世界~」の公開講座メモをまとめてみました。2019年に開催された際にメモを取っていたのですが、だいぶ長らく手元にしまい込んでいたため、今回改めてメモを整理して公開してみました。 他にも面白い話がいろいろとありましたので、またメモが発掘されたら公開するとともに、次回のクマ研講演会の開催を心待ちにしたいと思います。
Solaris10ではCPUアーキテクチャ名がコマンドになっている?
岩手県立大学とか、岩手の人たち Advent Calendar 1日目の記事です。 今日はSolaris10環境で提供されている(されていた?)謎のコマンドを紹介しようと思います。 (ただし我々の世界とは時間軸が完全に一致していない可能性があります...)
昨年の岩手県立大学 Advent Calendar 2020の記事でも話題に出しているように、学内のソフトウェア演習ではSolaris10が使用されています(繰り返しますが時間軸が異なっている可能性があります…)。
そんなSolaris10環境をあれこれいじっていると、シェル上で謎のコマンド名が補完されました。
$ mc mc68000 mc68010 mc68020 mc68030 mc68040 mconnect mcs
CPUアーキテクチャ名がコマンドになっている?
mc68000といえば、モトローラが開発したCPU(モトローラ的には「MPU(マイクロプロセッシングユニット)」と呼ぶようですね)です。このコマンドは何をするものなのでしょうか?
他にもCPUアーキテクチャ名がコマンドになっているものがいくつかあります。しかも他のCPUアーキテクチャに関しても同様にコマンドが提供されています。
$ file `which mc68000` `which sparc` `which pdp11` `which vax` `which i386` /bin/mc68000: ELF 32-bit LSB executable 80386 Version 1, dynamically linked, stripped /bin/sparc: ELF 32-bit LSB executable 80386 Version 1, dynamically linked, stripped /bin/pdp11: ELF 32-bit LSB executable 80386 Version 1, dynamically linked, stripped /bin/vax: ELF 32-bit LSB executable 80386 Version 1, dynamically linked, stripped /bin/i386: ELF 32-bit LSB executable 80386 Version 1, dynamically linked, stripped
加えて、iノード番号が同じであり、ファイル的には全て同じものとなっています。
$ ls -li `which mc68000` `which sparc` `which pdp11` `which vax` `which i386` 339 -r-xr-xr-x 29 root bin 5708 Jan 23 2005 /bin/i386* 339 -r-xr-xr-x 29 root bin 5708 Jan 23 2005 /bin/mc68000* 339 -r-xr-xr-x 29 root bin 5708 Jan 23 2005 /bin/pdp11* 339 -r-xr-xr-x 29 root bin 5708 Jan 23 2005 /bin/sparc* 339 -r-xr-xr-x 29 root bin 5708 Jan 23 2005 /bin/vax*
実行しても何かが起こるわけでもなく、単に終了コード 255 を返すだけです。
てっきり特定のCPUアーキテクチャのエミュレーション実行ツールか、あるいはバイナリ変換ツールかなと思っていたのですが、そうではなさそうです。
$ mc68000 ; echo $? 255
machid(1)コマンド
これら一連のコマンドが何であるかは、(当たり前ですが)ずばりmanページに記載されていました。
Solaris10が稼働しているマシンの命令セットと(コマンド名が)一致する場合に真(終了コード 0 )を返すコマンドとなっています。
$ man sparc User Commands machid(1) ... NAME machid, sun, iAPX286, i286, i386, i486, i860, pdp11, sparc, u3b, u3b2, u3b5, u3b15, vax, u370 - get processor type truth value ... DESCRIPTION The following commands will return a true value (exit code of 0) if you are using an instruction set that the command name indicates.
たしかに、マシンの命令セットと同じコマンドが真を返しています。
$ uname -a SunOS unknown 5.10 Generic_120012-14 i86pc i386 i86pc $ $ for cmd in i386 mc68000 pdp11 sparc vax ; do echo $cmd ; $cmd ; echo $? ; done | paste - - i386 0 mc68000 255 pdp11 255 sparc 255 vax 255
なるほど、これで疑問が解けてスッキリしました。Sun Microsystemsなのに何故か(?)Oracleのホームページでmachid(1)のマニュアルが参照できます。 が、マニュアルには以下の注意書きがあり、どうやら今回紹介した一連のコマンドはすでに非推奨のようです…。
machid コマンドファミリは廃止されており、Oracle Solaris の将来のリリースで削除される可能性があります。 代わりに uname -p を指定してください。
個人的には uname -p としても、 if [uname -p= 'i386' ]; then ... のような少し冗長な感じになりそうなので、単に i386 コマンド等の方がシンプルにも思えるのではありますが…。
まとめ
Solaris10で提供されていた、CPUアーキテクチャ名と同じという謎のコマンド群を紹介しました。BSD系やLinuxでは uname -p でマシン種別を判定したりしますが、歴史のあるUNIXではまたちょっと違った方法で判定するというトリビアを得られました。
SolarisのCDE環境に付属する謎(?)のツール、アプリケーションビルダ
遅ればせながら岩手県立大学 Advent Calendar 2020 第9日目の記事です。
今日はデスクトップ環境CDEに含まれている謎(?)のツール、「アプリケーションビルダ」の話をしようと思います。
(例によって我々の世界とは時間軸が完全に一致していない可能性があります...)

GUIアプリケーションビルダ?
ソフトウェア演習で利用しているSolarisには、「アプリケーションビルダ」という謎のツールが付属しています。謎、というのは、このツールの使い方がイマイチ良く分からないのに加え、マニュアルを見てもどうGUIを構築するのかがやはり見えてこない点にあります。
man dtbuilder によると、どうやらCDE向けのGUI管理機能を備えたアプリケーション構築ツールのようです。
$ man dtbuilder User Commands dtbuilder(1) Name dtbuilder - the CDE Application Builder SYNOPSIS dtbuilder [projectfile] DESCRIPTION The dtbuilder utility is an interactive application develop- ment tool and user interface management system for CDE. Known more fully as the CDE Application Builder, dtbuilder is designed to make it easier for developers to construct applications that integrate well into the CDE. It provides two basic services - aid in assembling Motif objects into the desired application user interface and generation of appropriate calls to the routines that support CDE desktop services (e.g. ToolTalk, sessioning, Help).
debuilder コマンドでアプリケーションビルダを起動できます。
$ which dtbuilder /usr/dt/bin/dtbuilder $ dtbuilder &
なにやらそっけない感じのウインドウが表示されます。

アプリケーションビルダでGUIを構築してみる
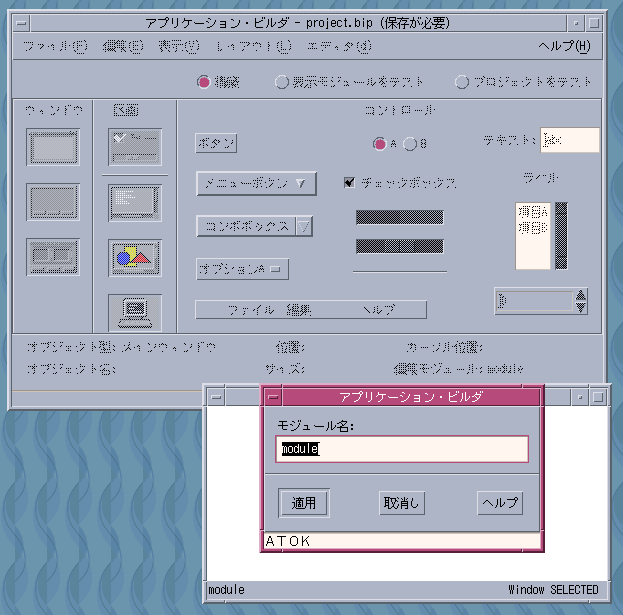
試しに簡単なGUIを作ってみます。左側の「ウインドウ」のアイコンをドラッグすると、「モジュール名」というダイアログが表示されます。どうやらこのようにしてアプリケーションウインドウを作ってゆくようです。
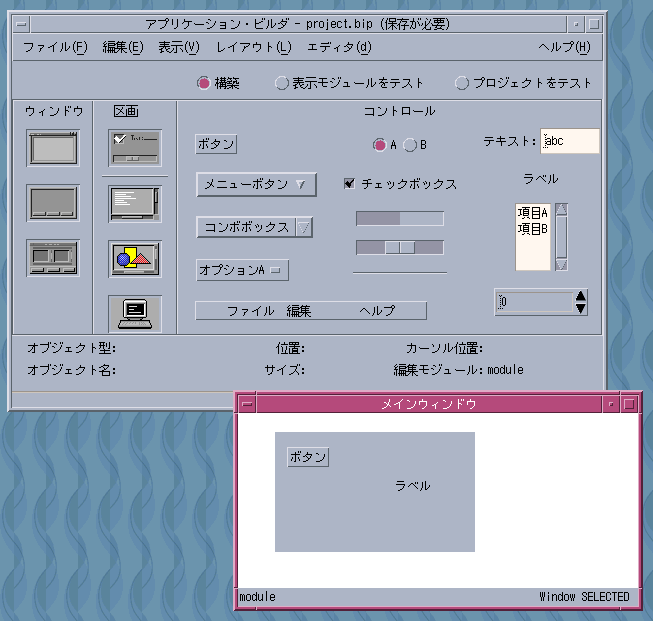
さらに「コントロール」ペインからボタンやラベルといったよく見かけるGUI部品をウインドウに配置してみます。
とりあえずビルドしてみる
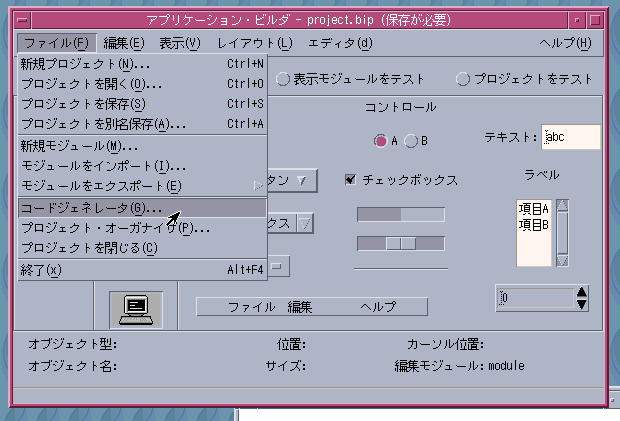
ビルドはどうすれば良いのだろうと思っていたのですが、どうやらアプリケーションビルダのメニューから「ファイル(F)」-「コードジェネレータ(G)...」で表示されるダイアログでコードの生成とmakeの実行まで行えることが分かりました。
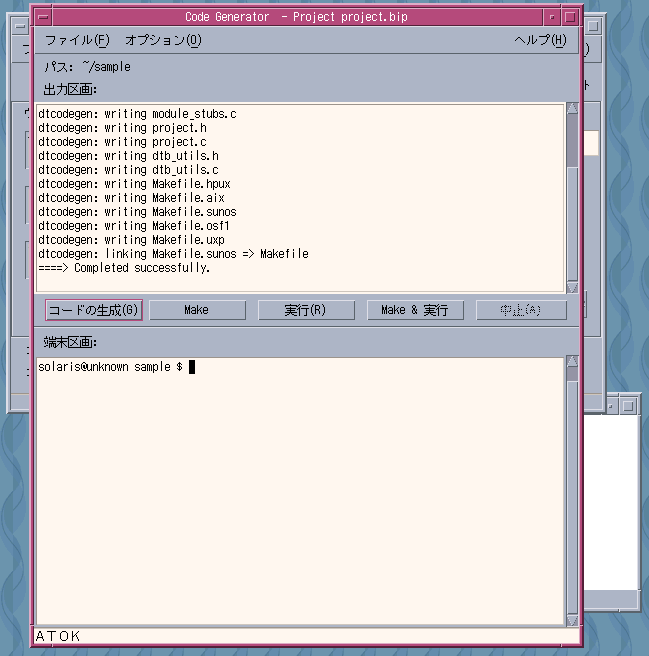
が、何やら make の実行でビルドエラーが出ます...。

落ち着いてエラーメッセージを読むと、 DTHELP_WARNING_DISABLED マクロを定義してビルドすると良いよ!的なことが書いてあります。 #define で指定する方法とCFLAGSに -DDTHELP_WARNING_DISABLED を追加するいずれかの方法で対応できそうだったので、今回はCFLAGSでマクロを定義する方法にしました。
$ diff -u Makefile.ORIG Makefile --- Makefile.ORIG Mon Dec 14 07:41:50 2020 +++ Makefile Mon Dec 14 07:42:30 2020 @@ -30,7 +30,7 @@ ALLX_LDFLAGS = -L$(ALLX_LIBPATH) -R$(ALLX_LIBPATH) LOCAL_LIBRARIES = -lDtWidget -lDtHelp -lDtSvc -lXm -lXt -lXext -lX11 - CFLAGS = $(CDEBUGFLAGS) $(INCLUDES) $(STD_DEFINES) $(ANSI_DEFINES) + CFLAGS = $(CDEBUGFLAGS) $(INCLUDES) $(STD_DEFINES) $(ANSI_DEFINES) -DDTHELP_WARNING_DISABLED CCFLAGS = $(CFLAGS) LDLIBS = $(SYS_LIBRARIES) LDOPTIONS = $(CDE_LDFLAGS) $(ALLX_LDFLAGS)
無事にビルドが通りました!

文字化けとの闘い
ビルドが通ったのは良いのですが、アプリケーションを実行してみるとボタンやラベルが文字化けしています...。

おそらくどこかに多言語向けのコード生成を行わせるようにする設定があるのでしょう。アプリケーションビルダのメニューを見ると、「エディタ(d)」-「アプリケーション・フレームワーク(A)」というメニューがあります。

そこには「国際化」という項目があり、デフォルト設定では「使用する:」のチェックが外れていました。このチェックを入れて再ビルドしてみます。

今度は無事に文字化けせずに表示できました!

まとめ
デスクトップ環境CDEに含まれているツール、アプリケーションビルダを簡単に触ってみました。実はこのツールはMotif)というGUIライブラリを利用してアプリケーションを構築するためのもので、どうやら9日目の記事で紹介したJava Swingよりもちょっと古いお作法でのGUIアプリケーション開発になるようなイメージです。
機会があれば、このアプリケーションビルダを利用してちょっとしたサンプルを作ってみたいと思います。